Basar el diseño del historial del navegador en la memoria del usuario
La usabilidad del historial del navegador podría ser mucho más útil si se rediseña pensando en cómo funciona la memoria del usuario. Es la acertada reflexión que hace Alex Faaborg, diseñador de experiencia de usuario en Mozilla y miembro del equipo de desarrollo de Firefox 3.
El objetivo del usuario cuando va al historial se podría resumir en algo como: "Yo vi algo en algún sitio hace poco y quiero volver ahí". Lo que normalmente hacemos para volver a encontrar esa información es ir al sitio donde lo vimos y recrear las acciones realizadas para volver a encontrar la información: esto suele ser más sencillo y rápido que usar el historial del navegador.
El problema es que el historial funciona mostrando una lista de titulos de páginas, además ordenados por orden alfabético y casi nadie se fija en el título de una página que, además, suele ser poco descriptivo.
Sin embargo hay elementos de la interacción con el navegador que son más fáciles de recordar:
- Acciones específicas que hizo: recordamos más facilmente lo que hemos hecho que dónde hemos estado. Por ejemplo: yo busqué tal palabra, guardé tal sitio en mis favoritos o ví el enlace en tal blog.
- El aspecto del sitio donde estuvimos: la ciencia cognitiva ha demostrado repetidamente que somos mucho mejores recordando imágenes que textos, especialmente en tareas de reconocimiento.
- Palabras o frases que leímos
- Cuándo hicimos algo: sabemos que hemos hecho algo hoy, ayer o hace varios días. No sabemos lo que hicimos hace exactamente 5 días o hace 7 días.
En base a estas premisas, algunas hipotéticas, pero muy lógicas, Faaborg hace una propuesta de rediseño del historial que se puede ver en este prototipo:
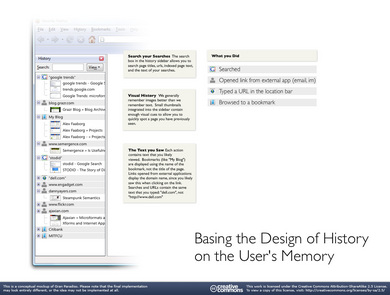
y que tendrÃa estas caracterÃsticas:
- Poder buscar sobre las búsquedas que has realizado
- Estaría organizado sobre segmentos de tiempo y acciones realizadas (buscar, abrir pestaña, pulsar link…). Cada segmento se agruparía sobre la acción que disparó la visualización de una serie concreta de páginas.
- Añadiría al título de la página una imagen en miniatura de la misma.
Una interesante propuesta que es posible que se convierta en una extensión para Firefox del laboratorio de Mozilla
Vía / Blog de Alex Faaborg