No entiendo por qué no hay un filter o un action cuando se trata de los contenidos de los widgets. A no ser que el autor los haya metido, no hay forma de modificar ni el form del widget ni su contenido.
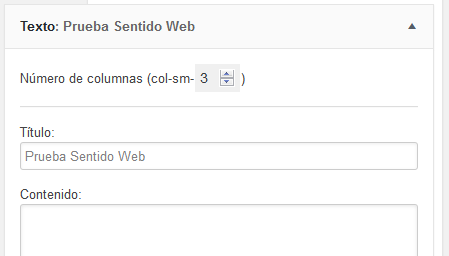
Me he encontrado en la necesidad de tener que indicar en el footer el tamaño de columnas de Bootstrap para cada uno de los widgets de un sidebar, para lo cual es necesario modificar la salida de cada widget e incluir en el form un campo que indique el ancho y en el html del widget el código de Bootstrap para indicar el ancho de la columna:
En el function.php meteremos el siguiente código:
Primero modificaremos los datos del widget para que añada el nuevo campo que vamos a meter (widget_bootstrap_columns), milagrosamente sí hay un filtro para ello:
// Modificamos los datos enviados al guardar el widget
add_filter( 'widget_update_callback', 'sw_widget_update');
function sw_widget_update($instance, $new_instance, $old_instance, $obj ) {
if (isset($_POST['widget_bootstrap_columns'])) $instance['widget_bootstrap_columns'] = $_POST['widget_bootstrap_columns'];
return $instance;
}
Después vamos a modificar la variable global $wp_registered_widgets que contiene la llamada a la función widget del widget (la que escribe el HTML). Encapsularemos esta llamada dentro de una función anónima para realizar las tareas que sean necesarias, en mi caso dibujar un div con el class col-sm-N:
// Modifico el display del widget para meterle el código de bootstrap
add_action('dynamic_sidebar_before', 'sw_modify_widgets_display', 10, 2);
function sw_modify_widgets_display($index, $bool) {
global $wp_registered_widgets;
$sidebars_widgets = wp_get_sidebars_widgets();
foreach ( (array) $sidebars_widgets[$index] as $id ) {
if ( !isset($wp_registered_widgets[$id]) ) continue;
$wp_registered_widgets[$id]['_callback'] = $wp_registered_widgets[$id]['callback'];
$wp_registered_widgets[$id]['callback'] = function($args, $widget_args) use ($id) {
global $wp_registered_widgets;
// Recuperamos los datos del widget
$instance = get_option($wp_registered_widgets[$id]['_callback'][0]->option_name);
$bootstrap = isset($instance[$wp_registered_widgets[$id]['_callback'][0]->number]['widget_bootstrap_columns'])? $instance[$wp_registered_widgets[$id]['_callback'][0]->number]['widget_bootstrap_columns'] : false;
// Pintamos el tamaño de la columna si así procede
if ($bootstrap) echo '<div class="col-sm-'.$bootstrap.'">';
call_user_func_array($wp_registered_widgets[$id]['_callback'], array($args, $widget_args));
if ($bootstrap) echo '</div>';
};
}
}
Y por último haremos lo mismo para el formulario, modificar la variable global $wp_registered_widget_controls para encapsular la función form del widget y dibujar antes un input donde almacenemos el valor de widget_bootstrap_columns:
// Modifica el form de los widgets
add_action( 'load-widgets.php', 'sw_modificar_widgets_forms' );
function sw_modificar_widgets_forms() {
global $wp_registered_widget_controls;
foreach($wp_registered_widget_controls as $id=>$widget) {
$wp_registered_widget_controls[$id]['_callback'] = $wp_registered_widget_controls[$id]['callback'];
$wp_registered_widget_controls[$id]['callback'] = function($data) use ($id) {
global $wp_registered_widget_controls;
// Recuperamos los datos del widget para incluir el valor de widget_bootstrap_columns
$instance = get_option($wp_registered_widget_controls[$id]['_callback'][0]->option_name);
$widget_bootstrap_columns = isset($instance[$data['number']]) && isset($instance[$data['number']]['widget_bootstrap_columns'])? $instance[$data['number']]['widget_bootstrap_columns']:'';
echo '<div class="widget_added"><p>Número de columnas (col-sm-<input type="number" name="widget_bootstrap_columns" min="1" max="12" value="'.$widget_bootstrap_columns.'" />)</p><hr /></div>';
call_user_func_array($wp_registered_widget_controls[$id]['_callback'], array($data));
};
}
}
Puedes bajarte el código en mi GitHub
 Debido a la decepción que me estoy llevando con el Zend Framework, aunque aún tengo esperanzas en que vaya mejorando, he tenido que buscar otras librerÃas PHP para crear PDF. Una que he encontrado que me está gustando bastante (por ahora) es FPDF, una librerÃa que exporta a PDF sin necesidad de PDFLib (la cual es de pago). Lo bueno que tiene tambien es que es gratuita, se puede usar libremente y modificar según nuestras necesidades.
Debido a la decepción que me estoy llevando con el Zend Framework, aunque aún tengo esperanzas en que vaya mejorando, he tenido que buscar otras librerÃas PHP para crear PDF. Una que he encontrado que me está gustando bastante (por ahora) es FPDF, una librerÃa que exporta a PDF sin necesidad de PDFLib (la cual es de pago). Lo bueno que tiene tambien es que es gratuita, se puede usar libremente y modificar según nuestras necesidades.