Formatear el código como en Sentido Web
Para aquellos que les guste como formateamos los comentarios en Sentido Web, vamos a explicar el código creado por Choan:
El proceso que sigue es el siguiente:
- Obtener todos los elementos pre.
- Para cada pre leer el primer elemento code que tenga.
- Obtenemos el texto que contiene.
- Dividimos el texto en líneas.
- Por cada línea comprobamos si hay algun tipo de comentario, si hay comentario lo separamos en dos partes para luego darle distintos estilos, diferenciando así el formato del comentario.
- Nos creamos un elemento ol, y en cada li insertamos una línea obtenida anteriormente.
- Sustituimos el elemento pre por el ol.
Destripemos un poco el código:
Primero obtenemos las etiquetas pre, comprobando primero si se puede ejecutar este script (si existe el método getElementsByTagName)
function lipt() {
/* change to FALSE if you don't want to proccess comments (boogie buggy) */
var PROCCESS_COMMENTS = true;
if (!document.getElementsByTagName) {
return;
}
var ns = document.getElementsByTagName('html')[0].getAttribute('xmlns');
// look for pre tags in the doc
var pres = document.getElementsByTagName('pre');
if (0 == pres.length) {
return; // no pre tags, nothing to do
}
Por cada pre, obtenemos el primer elemento code que tenga y obtenemos el texto que contiene.
for (var i = 0; i < pres.length; i++) {
var pre = pres[i];
// search for the first code element inside the pre
var code = pre.getElementsByTagName('code')[0];
if (null == code) {
continue; // no one here, try with the next pre tag
}
// go for the job
var inMultiLineComment = false;
var inHtmlComment = false;
var content = getText(code);Se normalizan las saltos de línea (solo habrá \n y no otro tipo de codificación) y obtenemos las líneas para tratarlas individualmente.
// normalize new lines
if (!window.opera) { /* Opera seems to have a nice bug with global replacements */
content = content.replace(/\n|\r|\r\n/g, '\n');
} else {
content = content.replace(/\n|\r|\r\n/, '\n');
}
content = content.replace(/^\n*/, ''); /* trim empty lines at start */
content = content.replace(/\n*$/, ''); /* trim empty lines at the end */
var lines = content.split('\n');Ya tenemos las líneas, ahora comprobamos si tiene comentarios, empezamos sustituyendo los tabuladores por cuatro espacios y contando cuantos espacios hay para diferenciando la profundidad en la tabulación con distintos estilos (que veremos más tarde).
var ol = createElement('ol', ns);
ol.className = 'code';
for (var j = 0; j < lines.length; j++) {
var line = lines[j];
line = line.replace(/\t/g, ' '); // replace tab with four spaces
var cname = 'tab' + (Math.floor(countSpaces(line) / 4)); // className for this line
var restSpaces = countSpaces(line) % 4;
line = line.replace(/^ +/, '');
if (restSpaces) {
for (var k = 0; k < restSpaces; k++) {
line = '\u00A0' + line; /* equivalent in Unicode */
}
}Empezamos a tratar las líneas comprobando si hay comentarios.
if (inMultiLineComment || inHtmlComment) {
parts = ['', line];
} else {
parts = [line];
}
if (PROCCESS_COMMENTS) {
var slashSlashPos = line.indexOf('//');
var starSlashPos = line.indexOf('/*');
var slashStarPos = line.indexOf('*/');
var htmlCmtStart = line.indexOf('');Hora de los comentarios, miramos cada tipo de comentarios y tenemos cuidado de que no se encuentren entre comillas u otros casos que invalide el comentario (por ejemplo http://, // no se trata de un comentario).
labelSlashSlash: if (slashSlashPos != -1) {
switch (line.charAt(slashSlashPos -1)) {
case '"':
case "'":
case ':': /* don't process URIs as comments */
break labelSlashSlash;
}
//parts = line.split('//');
//parts[1] = '//' + parts[1];
parts[0] = line.substring(0, slashSlashPos);
parts[1] = line.substring(slashSlashPos)
} else if (starSlashPos != -1) {
switch (line.charAt(starSlashPos -1)) {
case '"':
case "'":
break labelSlashSlash;
}
if (!inMultiLineComment) {
parts = line.split('/*');
parts[1] = '/*' + parts[1];
}
inMultiLineComment = true;
}
labelHtmlCmt: if (htmlCmtStart != -1) {
switch (line.charAt(htmlCmtStart -1)) {
case '"':
case "'":
break labelHtmlCmt;
}
if (!inHtmlComment) {
parts = line.split('
Similar Posts
YAML: framework CSS
YAML (Yet Another Multicolumn Layout) es un framework XHTML/CSS que nos permite crear plantillas para diseños web proporcionandonos diferentes tipos de layouts. Está basado en estándares, es sencillo de usar y comprobado en sitios web profesionales.
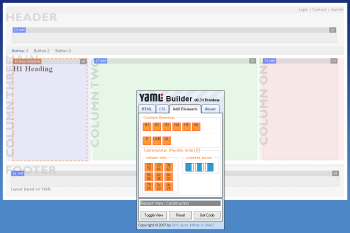
A parte, nos ofrece una herramienta online para crear nuestros propios diseños de forma rápida y sencilla. Tan solo deberemos indicar el tipo de diseño, los tamaños, podremos añadirle elementos HTML y por último recuperar el código fuente.
YAML
VÃa / Ajaxian
Mini parser para código PHP
En mi blog personal, me ocurre que cuando quiero mostrar código en un post tengo que modificarlo para que quede bonito, poniéndole estilos, etc… La verdad es que es bastante aburrido y no es algo que me guste mucho hacer, me da mucha pereza.
Supongo que hay más gente que se encuentra en mi situación y me entenderán. La solución es usar unas librerías que me modifiquen el código y lo muestre con colores y tabulado. No me he puesto a buscar en Google, pero habrá ya alguna, de todas formas, siempre está bien saber cómo se podría hacer.
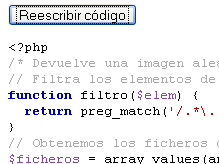
En este caso vamos a explicar como realizar un pequeño parser de código PHP, con tan solo unas funcionalidades: reconoce comentarios, palabras reservadas, funciones, variables y texto entrecomillado, a parte de realizar una mínima tabulación. No reconoce código HTML, ni realiza otras cosas, aunque las ampliaciones son posibles.